- 개발 환경(OS): Windows 10 Education, 64비트 운영 체제, x64 기반 프로세서

Library version check¶
import sys
import sktime
import tqdm as tq
import xgboost as xgb
import matplotlib
import seaborn as sns
import sklearn as skl
import pandas as pd
import numpy as np
print("-------------------------- Python & library version --------------------------")
print("Python version: {}".format(sys.version))
print("pandas version: {}".format(pd.__version__))
print("numpy version: {}".format(np.__version__))
print("matplotlib version: {}".format(matplotlib.__version__))
print("tqdm version: {}".format(tq.__version__))
print("sktime version: {}".format(sktime.__version__))
print("xgboost version: {}".format(xgb.__version__))
print("seaborn version: {}".format(sns.__version__))
print("scikit-learn version: {}".format(skl.__version__))
print("------------------------------------------------------------------------------")
0. load the libararies¶
import matplotlib.pyplot as plt
from tqdm import tqdm
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting import plot_series
from xgboost import XGBRegressor
pd.set_option('display.max_columns', 30)
1. preprocessing the data¶
- time series를 일반 regression 문제로 변환하기 위해 시간 관련 변수 추가(월 / 주 / 요일)¶
- 전력소비량의 건물별 요일별 시간대별 평균 / 건물별 시간대별 평균 / 건물별 시간대별 표준편차 변수 추가¶
건물별 요일별 시간대별 표준편차 / 건물별 평균 등 여러 통계량 생성 후 몇개 건물에 테스트, 최종적으로 성능 향상에 도움이 된 위 3개 변수만 추가¶
- 공휴일 변수 추가¶
- 시간(hour)는 cyclical encoding하여 변수 추가(sin time & cos time) 후 삭제¶
- CDH(Cooling Degree Hour) & THI(불쾌지수) 변수 추가¶
- 건물별 모델 생성 시 무의미한 태양광 발전 시설 / 냉방시설 변수 삭제¶
train = pd.read_csv('./data/train.csv', encoding = 'cp949')
## 변수들을 영문명으로 변경
cols = ['num', 'date_time', 'power', 'temp', 'wind','hum' ,'prec', 'sun', 'non_elec', 'solar']
train.columns = cols
# 시간 관련 변수들 생성
date = pd.to_datetime(train.date_time)
train['hour'] = date.dt.hour
train['day'] = date.dt.weekday
train['month'] = date.dt.month
train['week'] = date.dt.weekofyear
#######################################
## 건물별, 요일별, 시간별 발전량 평균 넣어주기
#######################################
power_mean = pd.pivot_table(train, values = 'power', index = ['num', 'hour', 'day'], aggfunc = np.mean).reset_index()
tqdm.pandas()
train['day_hour_mean'] = train.progress_apply(lambda x : power_mean.loc[(power_mean.num == x['num']) & (power_mean.hour == x['hour']) & (power_mean.day == x['day']) ,'power'].values[0], axis = 1)
#######################################
## 건물별 시간별 발전량 평균 넣어주기
#######################################
power_hour_mean = pd.pivot_table(train, values = 'power', index = ['num', 'hour'], aggfunc = np.mean).reset_index()
tqdm.pandas()
train['hour_mean'] = train.progress_apply(lambda x : power_hour_mean.loc[(power_hour_mean.num == x['num']) & (power_hour_mean.hour == x['hour']) ,'power'].values[0], axis = 1)
#######################################
## 건물별 시간별 발전량 표준편차 넣어주기
#######################################
power_hour_std = pd.pivot_table(train, values = 'power', index = ['num', 'hour'], aggfunc = np.std).reset_index()
tqdm.pandas()
train['hour_std'] = train.progress_apply(lambda x : power_hour_std.loc[(power_hour_std.num == x['num']) & (power_hour_std.hour == x['hour']) ,'power'].values[0], axis = 1)
### 공휴일 변수 추가
train['holiday'] = train.apply(lambda x : 0 if x['day']<5 else 1, axis = 1)
train.loc[('2020-08-17'<=train.date_time)&(train.date_time<'2020-08-18'), 'holiday'] = 1
## https://dacon.io/competitions/official/235680/codeshare/2366?page=1&dtype=recent
train['sin_time'] = np.sin(2*np.pi*train.hour/24)
train['cos_time'] = np.cos(2*np.pi*train.hour/24)
## https://dacon.io/competitions/official/235736/codeshare/2743?page=1&dtype=recent
train['THI'] = 9/5*train['temp'] - 0.55*(1-train['hum']/100)*(9/5*train['hum']-26)+32
def CDH(xs):
ys = []
for i in range(len(xs)):
if i < 11:
ys.append(np.sum(xs[:(i+1)]-26))
else:
ys.append(np.sum(xs[(i-11):(i+1)]-26))
return np.array(ys)
cdhs = np.array([])
for num in range(1,61,1):
temp = train[train['num'] == num]
cdh = CDH(temp['temp'].values)
cdhs = np.concatenate([cdhs, cdh])
train['CDH'] = cdhs
train.drop(['non_elec','solar','hour'], axis = 1, inplace = True)
train.head()
## save the preprocessed data
train.to_csv('./data/train_preprocessed.csv')
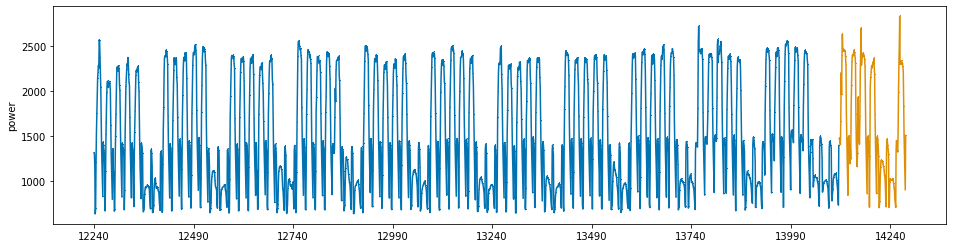
sktime library으로 마지막 일주일을 validation set으로 설정¶
## 7번 건물의 발전량
y = train.loc[train.num == 7, 'power']
x = train.loc[train.num == 7, ].iloc[:, 3:]
y_train, y_valid, x_train, x_valid = temporal_train_test_split(y = y, X = x, test_size = 168) # 24시간*7일 = 168
print('train data shape\nx:{}, y:{}'.format(x_train.shape, y_train.shape))
plot_series(y_train, y_valid, markers=[',' , ','])
plt.show()
2. Model : XGBoost¶
모델은 시계열 데이터에 좋은 성능을 보이는 XGBoost를 선정했습니다.¶
# Define SMAPE loss function
def SMAPE(true, pred):
return np.mean((np.abs(true-pred))/(np.abs(true) + np.abs(pred))) * 100
print("실제값이 100일 때 50으로 underestimate할 때의 SMAPE : {}".format(SMAPE(100, 50)))
print("실제값이 100일 때 150으로 overestimate할 때의 SMAPE : {}".format(SMAPE(100, 150)))
그러나 일반 mse를 objective function으로 훈련할 때 과소추정하는 건물들이 있음을 확인했습니다.¶
이때문에 SMAPE 점수가 높아진다고 판단, 이를 해결하기 위해 아래와 같이 objective function을 새로 정의했습니다.¶
새 목적함수는 residual이 0보다 클 때, 즉 실제값보다 낮게 추정할 때 alpha만큼의 가중치를 곱해 반영합니다.¶
XGBoost는 custom objective function으로 훈련하기 위해선 아래와 같이¶
gradient(1차 미분함수) / hessian(2차 미분함수)를 정의해 두 값을 return해주어야 합니다.¶
#### alpha를 argument로 받는 함수로 실제 objective function을 wrapping하여 alpha값을 쉽게 조정할 수 있도록 작성했습니다.
# custom objective function for forcing model not to underestimate
def weighted_mse(alpha = 1):
def weighted_mse_fixed(label, pred):
residual = (label - pred).astype("float")
grad = np.where(residual>0, -2*alpha*residual, -2*residual)
hess = np.where(residual>0, 2*alpha, 2.0)
return grad, hess
return weighted_mse_fixed
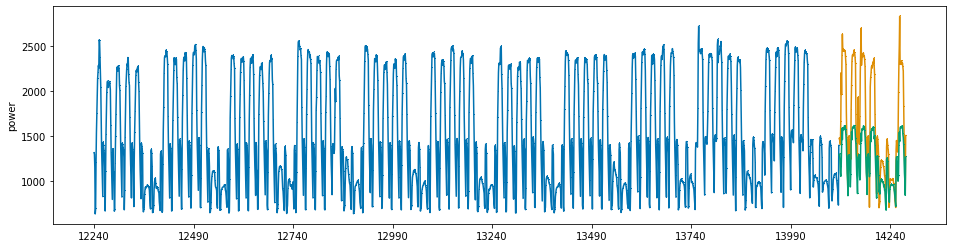
기본 mse를 objective function으로 사용할 때 : SAMPE 12.7705¶
xgb_params = pd.read_csv('./parameters/hyperparameter_xgb.csv')
xgb_reg = XGBRegressor(n_estimators = 10000, eta = xgb_params.iloc[47,1], min_child_weight = xgb_params.iloc[47,2],
max_depth = xgb_params.iloc[47,3], colsample_bytree = xgb_params.iloc[47,4],
subsample = xgb_params.iloc[47,5], seed=0)
xgb_reg.fit(x_train, y_train, eval_set=[(x_train, y_train), (x_valid, y_valid)],
early_stopping_rounds=300,
verbose=False)
## 주황색이 실제 전력소비량, 초록색이 예측값입니다.
pred = xgb_reg.predict(x_valid)
pred = pd.Series(pred)
pred.index = np.arange(y_valid.index[0], y_valid.index[-1]+1)
plot_series(y_train, y_valid, pd.Series(pred), markers=[',' , ',', ','])
print('best iterations: {}'.format(xgb_reg.best_iteration))
print('SMAPE : {}'.format(SMAPE(y_valid, pred)))
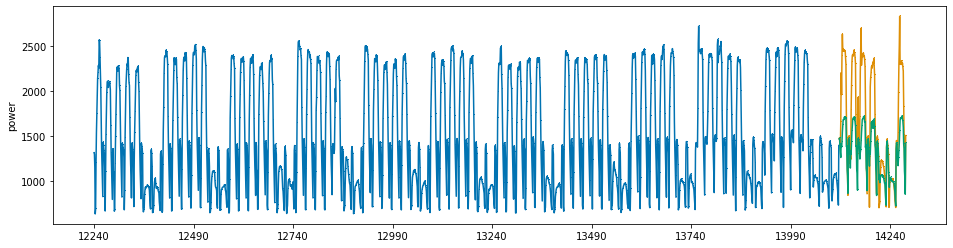
with weighted mse(alpha = 100) : SMAPE 9.9390¶
xgb_reg = XGBRegressor(n_estimators = 10000, eta = xgb_params.iloc[47,1], min_child_weight = xgb_params.iloc[47,2],
max_depth = xgb_params.iloc[47,3], colsample_bytree = xgb_params.iloc[47,4],
subsample = xgb_params.iloc[47,5], seed=0)
xgb_reg.set_params(**{'objective':weighted_mse(100)})
xgb_reg.fit(x_train, y_train, eval_set=[(x_train, y_train), (x_valid, y_valid)],
early_stopping_rounds=300,
verbose=False)
## SMAPE 값으로도, 그래프 상으로도 과소추정이 모델이 개선되었음을 확인
pred = xgb_reg.predict(x_valid)
pred = pd.Series(pred)
pred.index = np.arange(y_valid.index[0], y_valid.index[-1]+1)
plot_series(y_train, y_valid, pd.Series(pred), markers=[',' , ',', ','])
print('best iterations: {}'.format(xgb_reg.best_iteration))
print('SMAPE : {}'.format(SMAPE(y_valid, pred)))
3. model tuning¶
## gridsearchCV for best model : 대략 1시간 소요
"""
from sklearn.model_selection import PredefinedSplit, GridSearchCV
df = pd.DataFrame(columns = ['n_estimators', 'eta', 'min_child_weight','max_depth', 'colsample_bytree', 'subsample'])
preds = np.array([])
grid = {'n_estimators' : [100], 'eta' : [0.01], 'min_child_weight' : np.arange(1, 8, 1),
'max_depth' : np.arange(3,9,1) , 'colsample_bytree' :np.arange(0.8, 1.0, 0.1),
'subsample' :np.arange(0.8, 1.0, 0.1)} # fix the n_estimators & eta(learning rate)
for i in tqdm(np.arange(1, 61)):
y = train.loc[train.num == i, 'power']
x = train.loc[train.num == i, ].iloc[:, 3:]
y_train, y_test, x_train, x_test = temporal_train_test_split(y = y, X = x, test_size = 168)
pds = PredefinedSplit(np.append(-np.ones(len(x)-168), np.zeros(168)))
gcv = GridSearchCV(estimator = XGBRegressor(seed = 0, gpu_id = 1,
tree_method = 'gpu_hist', predictor= 'gpu_predictor'),
param_grid = grid, scoring = smape, cv = pds, refit = True, verbose = True)
gcv.fit(x_train, y_train)
best = gcv.best_estimator_
params = gcv.best_params_
print(params)
pred = best.predict(x_test)
building = 'building'+str(i)
print(building + '|| SMAPE : {}'.format(SMAPE(y_test, pred)))
preds = np.append(preds, pred)
df = pd.concat([df, pd.DataFrame(params, index = [0])], axis = 0)
df.to_csv('./hyperparameter_xgb.csv', index = False) # save the tuned parameters
"""
xgb_params = pd.read_csv('./parameters/hyperparameter_xgb.csv')
find the bset iteration (given alpha = 100)¶
scores = [] # smape 값을 저장할 list
best_it = [] # best interation을 저장할 list
for i in tqdm(range(60)):
y = train.loc[train.num == i+1, 'power']
x = train.loc[train.num == i+1, ].iloc[:, 3:]
y_train, y_valid, x_train, x_valid = temporal_train_test_split(y = y, X = x, test_size = 168)
xgb_reg = XGBRegressor(n_estimators = 10000, eta = 0.01, min_child_weight = xgb_params.iloc[i, 2],
max_depth = xgb_params.iloc[i, 3], colsample_bytree = xgb_params.iloc[i, 4],
subsample = xgb_params.iloc[i, 5], seed=0)
xgb_reg.set_params(**{'objective':weighted_mse(100)}) # alpha = 100으로 고정
xgb_reg.fit(x_train, y_train, eval_set=[(x_train, y_train),
(x_valid, y_valid)], early_stopping_rounds=300, verbose=False)
y_pred = xgb_reg.predict(x_valid)
pred = pd.Series(y_pred)
sm = SMAPE(y_valid, y_pred)
scores.append(sm)
best_it.append(xgb_reg.best_iteration) ## 실제 best iteration은 이 값에 +1 해주어야 함.
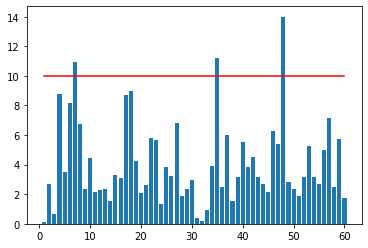
alpha tuning for weighted MSE¶
alpha_list = []
smape_list = []
for i in tqdm(range(60)):
y = train.loc[train.num == i+1, 'power']
x = train.loc[train.num == i+1, ].iloc[:, 3:]
y_train, y_test, x_train, x_test = temporal_train_test_split(y = y, X = x, test_size = 168)
xgb = XGBRegressor(seed = 0,
n_estimators = best_it[i], eta = 0.01, min_child_weight = xgb_params.iloc[i, 2],
max_depth = xgb_params.iloc[i, 3], colsample_bytree = xgb_params.iloc[i, 4], subsample = xgb_params.iloc[i, 5])
xgb.fit(x_train, y_train)
pred0 = xgb.predict(x_test)
best_alpha = 0
score0 = SMAPE(y_test,pred0)
for j in [1, 3, 5, 7, 10, 25, 50, 75, 100]:
xgb = XGBRegressor(seed = 0,
n_estimators = best_it[i], eta = 0.01, min_child_weight = xgb_params.iloc[i, 2],
max_depth = xgb_params.iloc[i, 3], colsample_bytree = xgb_params.iloc[i, 4], subsample = xgb_params.iloc[i, 5])
xgb.set_params(**{'objective' : weighted_mse(j)})
xgb.fit(x_train, y_train)
pred1 = xgb.predict(x_test)
score1 = SMAPE(y_test, pred1)
if score1 < score0:
best_alpha = j
score0 = score1
alpha_list.append(best_alpha)
smape_list.append(score0)
print("building {} || best score : {} || alpha : {}".format(i+1, score0, best_alpha))
no_df = pd.DataFrame({'score':smape_list})
plt.bar(np.arange(len(no_df))+1, no_df['score'])
plt.plot([1,60], [10, 10], color = 'red')
4. test inference¶
preprocessing for test data¶
# train set과 동일한 전처리 과정
test = pd.read_csv('./data/test.csv', encoding = 'cp949')
cols = ['num', 'date_time', 'temp', 'wind','hum' ,'prec', 'sun', 'non_elec', 'solar']
test.columns = cols
date = pd.to_datetime(test.date_time)
test['hour'] = date.dt.hour
test['day'] = date.dt.weekday
test['month'] = date.dt.month
test['week'] = date.dt.weekofyear
test['sin_time'] = np.sin(2*np.pi*test.hour/24)
test['cos_time'] = np.cos(2*np.pi*test.hour/24)
test['holiday'] = test.apply(lambda x : 0 if x['day']<5 else 1, axis = 1)
test.loc[('2020-08-17'<=test.date_time)&(test.date_time<'2020-08-18'), 'holiday'] = 1
## 건물별 일별 시간별 발전량 평균
tqdm.pandas()
test['day_hour_mean'] = test.progress_apply(lambda x : power_mean.loc[(power_mean.num == x['num']) & (power_mean.day == x['day']) & (power_mean.hour == x['hour']) ,'power'].values[0], axis = 1)
## 건물별 시간별 발전량 평균 넣어주기
tqdm.pandas()
test['hour_mean'] = test.progress_apply(lambda x : power_hour_mean.loc[(power_hour_mean.num == x['num']) & (power_hour_mean.hour == x['hour']) ,'power'].values[0], axis = 1)
tqdm.pandas()
test['hour_std'] = test.progress_apply(lambda x : power_hour_std.loc[(power_hour_std.num == x['num']) & (power_hour_std.hour == x['hour']) ,'power'].values[0], axis = 1)
test.drop(['non_elec', 'solar','hour','date_time'], axis = 1, inplace = True)
# pandas 내 선형보간 method 사용
for i in range(60):
test.iloc[i*168:(i+1)*168, :] = test.iloc[i*168:(i+1)*168, :].interpolate()
test['THI'] = 9/5*test['temp'] - 0.55*(1-test['hum']/100)*(9/5*test['hum']-26)+32
cdhs = np.array([])
for num in range(1,61,1):
temp = test[test['num'] == num]
cdh = CDH(temp['temp'].values)
cdhs = np.concatenate([cdhs, cdh])
test['CDH'] = cdhs
test = test[['num','temp', 'wind', 'hum', 'prec', 'sun', 'day', 'month', 'week',
'day_hour_mean', 'hour_mean', 'hour_std', 'holiday', 'sin_time',
'cos_time', 'THI', 'CDH']]
test.head()
xgb_params['alpha'] = alpha_list
xgb_params['best_it'] = best_it
xgb_params.head()
#xgb_params.to_csv('./hyperparameter_xgb_final.csv', index=False)
## best hyperparameters 불러오기
xgb_params = pd.read_csv('./parameters/hyperparameter_xgb_final.csv')
xgb_params.head()
best_it = xgb_params['best_it'].to_list()
best_it[0] # 1051
preds = np.array([])
for i in tqdm(range(60)):
pred_df = pd.DataFrame() # 시드별 예측값을 담을 data frame
for seed in [0,1,2,3,4,5]: # 각 시드별 예측
y_train = train.loc[train.num == i+1, 'power']
x_train, x_test = train.loc[train.num == i+1, ].iloc[:, 3:], test.loc[test.num == i+1, ].iloc[:,1:]
x_test = x_test[x_train.columns]
xgb = XGBRegressor(seed = seed, n_estimators = best_it[i], eta = 0.01,
min_child_weight = xgb_params.iloc[i, 2], max_depth = xgb_params.iloc[i, 3],
colsample_bytree=xgb_params.iloc[i, 4], subsample=xgb_params.iloc[i, 5])
if xgb_params.iloc[i,6] != 0: # 만약 alpha가 0이 아니면 weighted_mse 사용
xgb.set_params(**{'objective':weighted_mse(xgb_params.iloc[i,6])})
xgb.fit(x_train, y_train)
y_pred = xgb.predict(x_test)
pred_df.loc[:,seed] = y_pred # 각 시드별 예측 담기
pred = pred_df.mean(axis=1) # (i+1)번째 건물의 예측 = (i+1)번째 건물의 각 시드별 예측 평균값
preds = np.append(preds, pred)
preds = pd.Series(preds)
fig, ax = plt.subplots(60, 1, figsize=(100,200), sharex = True)
ax = ax.flatten()
for i in range(60):
train_y = train.loc[train.num == i+1, 'power'].reset_index(drop = True)
test_y = preds[i*168:(i+1)*168]
ax[i].scatter(np.arange(2040) , train.loc[train.num == i+1, 'power'])
ax[i].scatter(np.arange(2040, 2040+168) , test_y)
ax[i].tick_params(axis='both', which='major', labelsize=6)
ax[i].tick_params(axis='both', which='minor', labelsize=4)
#plt.savefig('./predict_xgb.png')
plt.show()

submission = pd.read_csv('./data/sample_submission.csv')
submission['answer'] = preds
submission.to_csv('./submission/submission_xgb_noclip.csv', index = False)
5. post processing¶
train_to_post = pd.read_csv('./data/train.csv', encoding = 'cp949')
cols = ['num', 'date_time', 'power', 'temp', 'wind','hum' ,'prec', 'sun', 'non_elec', 'solar']
train_to_post.columns = cols
date = pd.to_datetime(train_to_post.date_time)
train_to_post['hour'] = date.dt.hour
train_to_post['day'] = date.dt.weekday
train_to_post['month'] = date.dt.month
train_to_post['week'] = date.dt.weekofyear
train_to_post = train_to_post.loc[(('2020-08-17'>train_to_post.date_time)|(train_to_post.date_time>='2020-08-18')), ].reset_index(drop = True)
pred_clip = []
test_to_post = pd.read_csv('./data/test.csv', encoding = 'cp949')
cols = ['num', 'date_time', 'temp', 'wind','hum' ,'prec', 'sun', 'non_elec', 'solar']
test_to_post.columns = cols
date = pd.to_datetime(test_to_post.date_time)
test_to_post['hour'] = date.dt.hour
test_to_post['day'] = date.dt.weekday
test_to_post['month'] = date.dt.month
test_to_post['week'] = date.dt.weekofyear
## submission 불러오기
df = pd.read_csv('./submission/submission_xgb_noclip.csv')
for i in range(60):
min_data = train_to_post.loc[train_to_post.num == i+1, ].iloc[-28*24:, :] ## 건물별로 직전 28일의 데이터 불러오기
## 요일별, 시간대별 최솟값 계산
min_data = pd.pivot_table(min_data, values = 'power', index = ['day', 'hour'], aggfunc = min).reset_index()
pred = df.answer[168*i:168*(i+1)].reset_index(drop=True) ## 168개 데이터, 즉 건물별 예측값 불러오기
day = test_to_post.day[168*i:168*(i+1)].reset_index(drop=True) ## 예측값 요일 불러오기
hour = test_to_post.hour[168*i:168*(i+1)].reset_index(drop=True) ## 예측값 시간 불러오기
df_pred = pd.concat([pred, day, hour], axis = 1)
df_pred.columns = ['pred', 'day', 'hour']
for j in range(len(df_pred)):
min_power = min_data.loc[(min_data.day == df_pred.day[j])&(min_data.hour == df_pred.hour[j]), 'power'].values[0]
if df_pred.pred[j] < min_power:
pred_clip.append(min_power)
else:
pred_clip.append(df_pred.pred[j])
pred_origin = df.answer
pred_clip = pd.Series(pred_clip)
for i in range(60):
power = train_to_post.loc[train_to_post.num == i+1, 'power'].reset_index(drop=True)
preds = pred_clip[i*168:(i+1)*168]
preds_origin = pred_origin[i*168:(i+1)*168]
preds.index = range(power.index[-1], power.index[-1]+168)
preds_origin.index = range(power.index[-1], power.index[-1]+168)
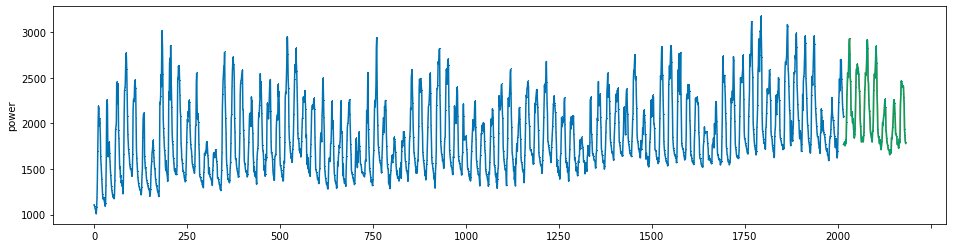
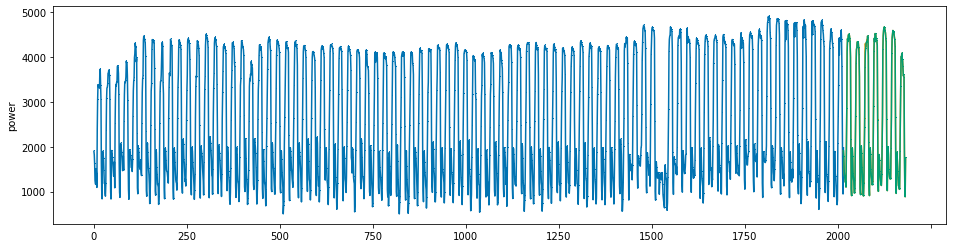
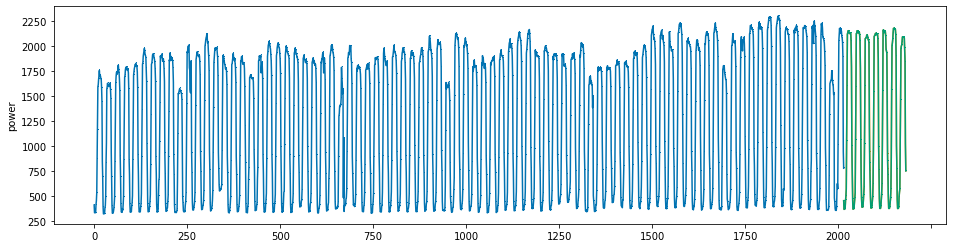
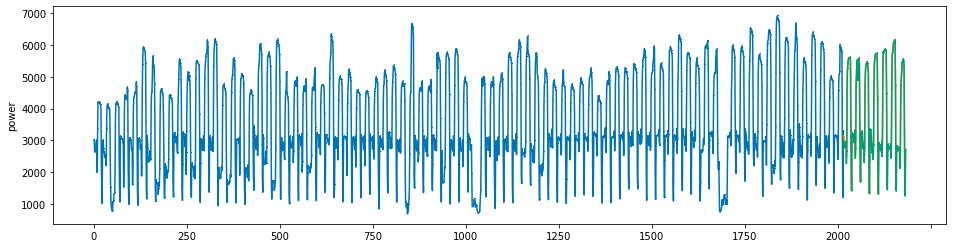
plot_series(power, preds, preds_origin, markers = [',', ',', ','])
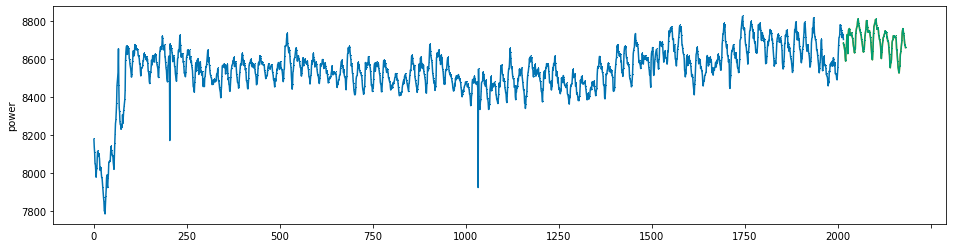
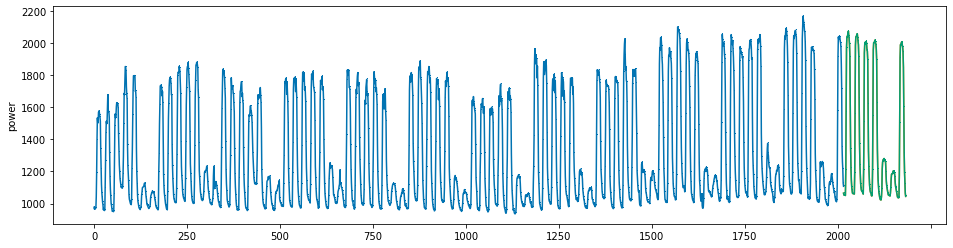
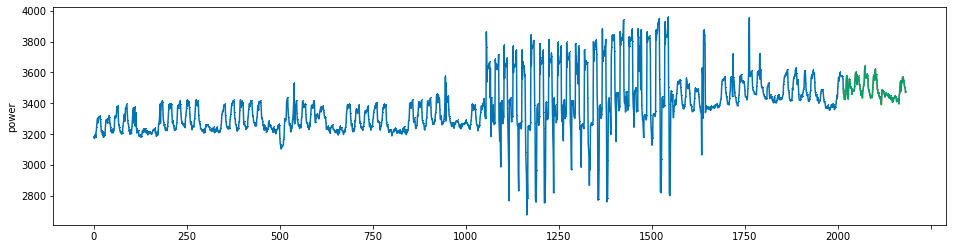
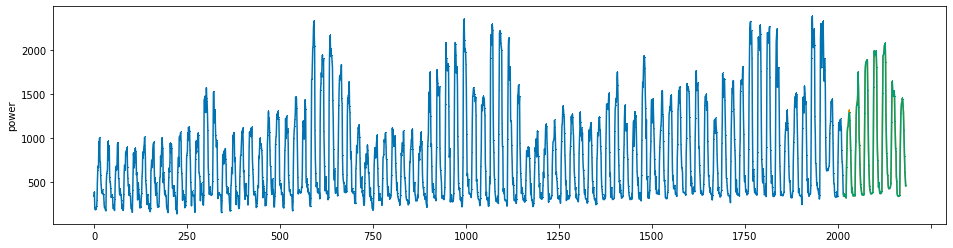
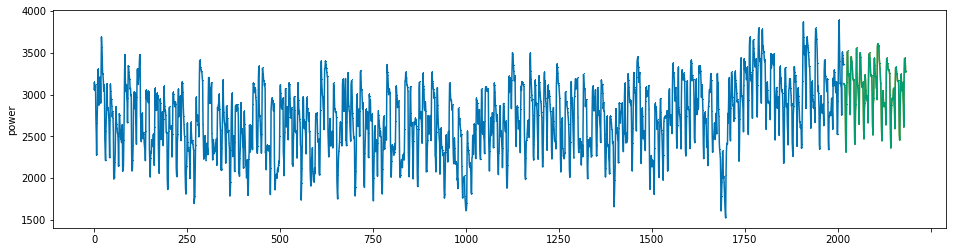
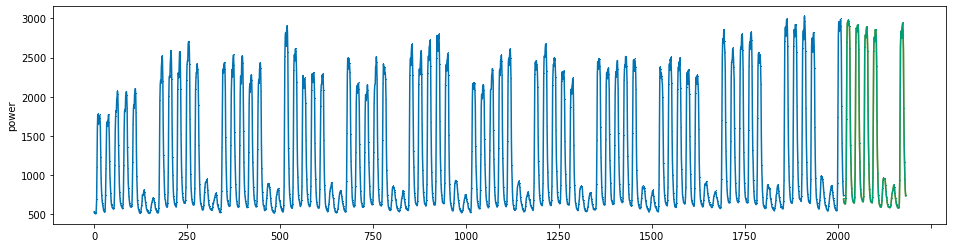

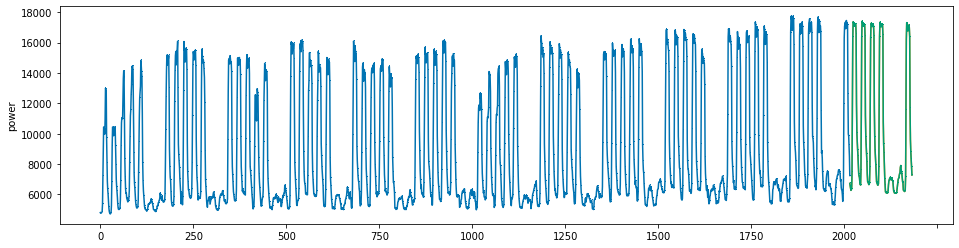
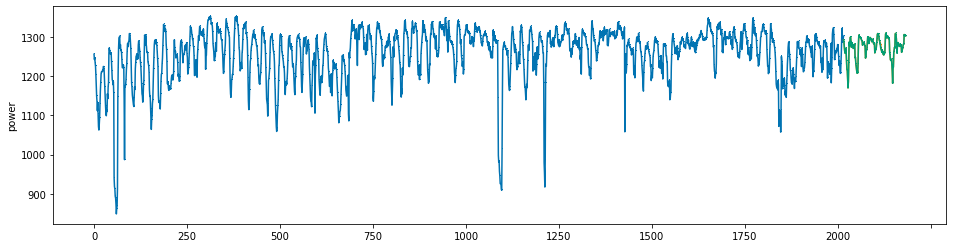
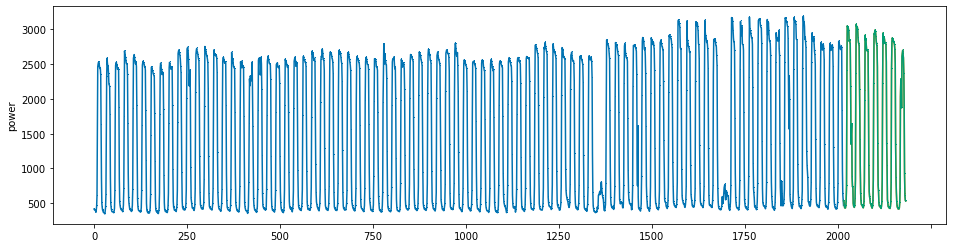
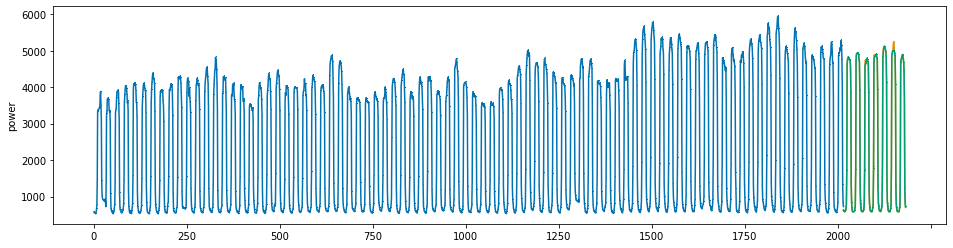
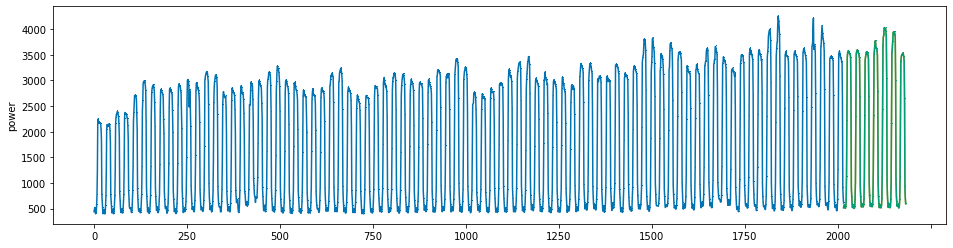
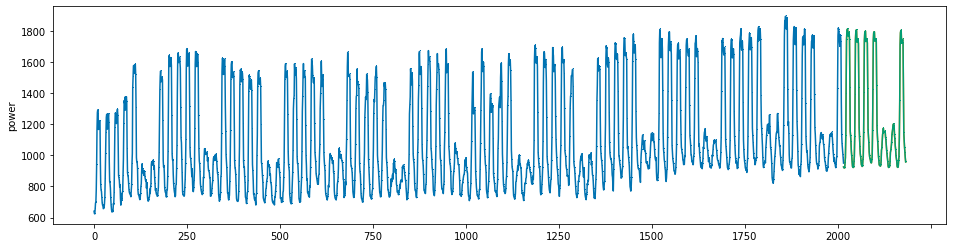
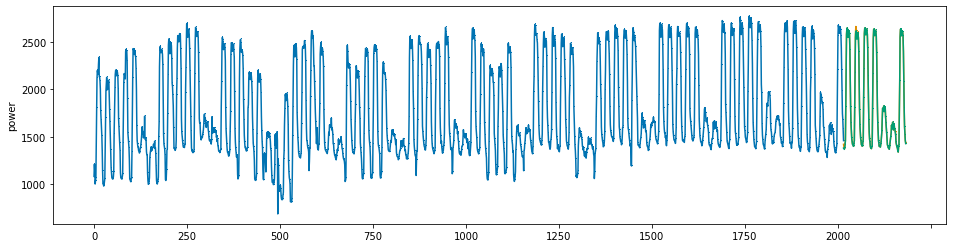
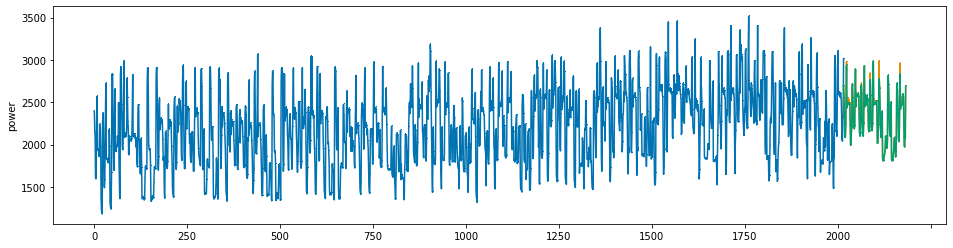
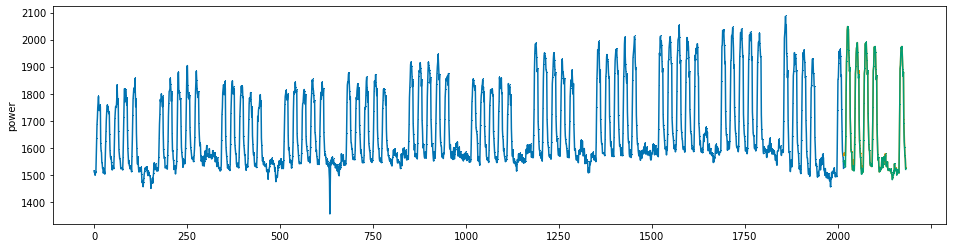
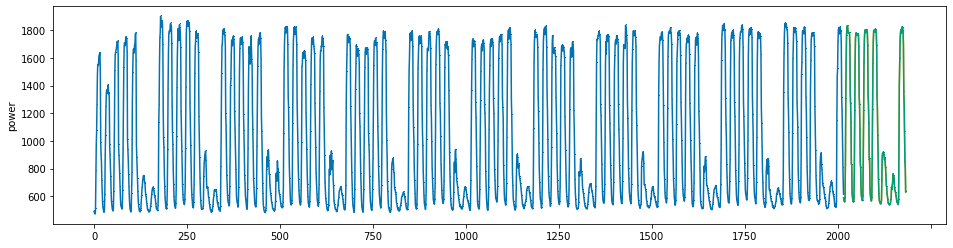

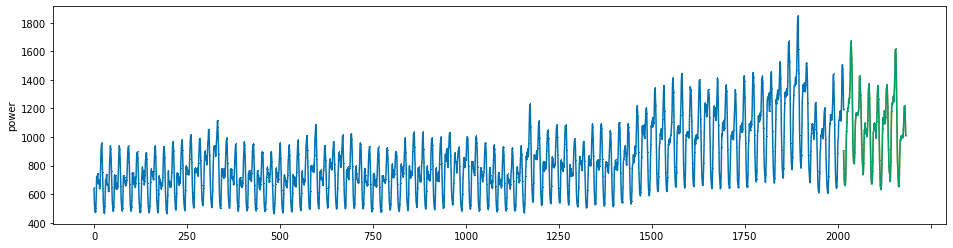
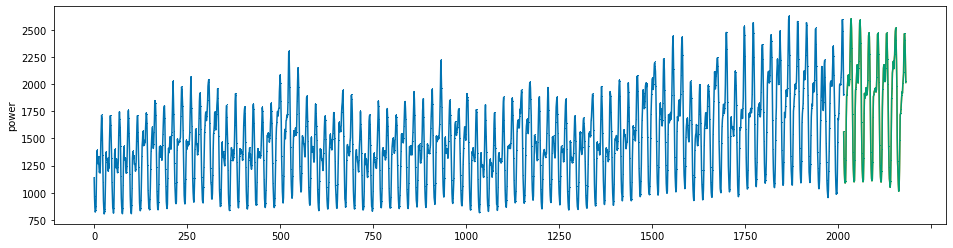
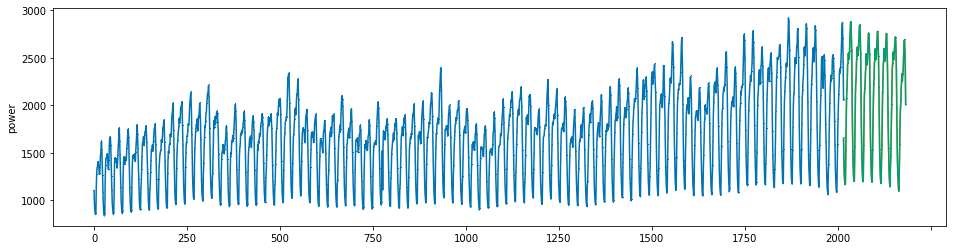
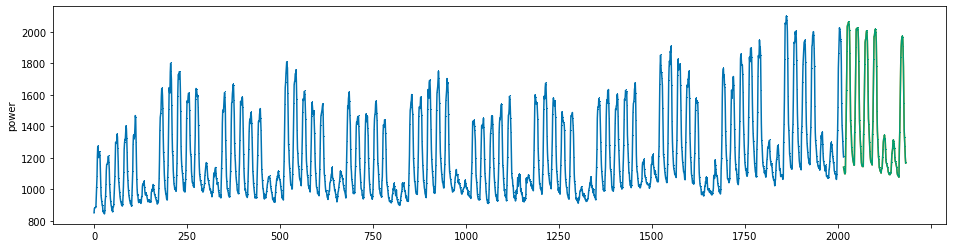

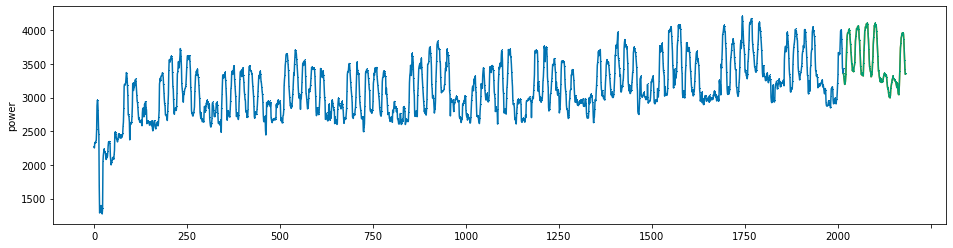
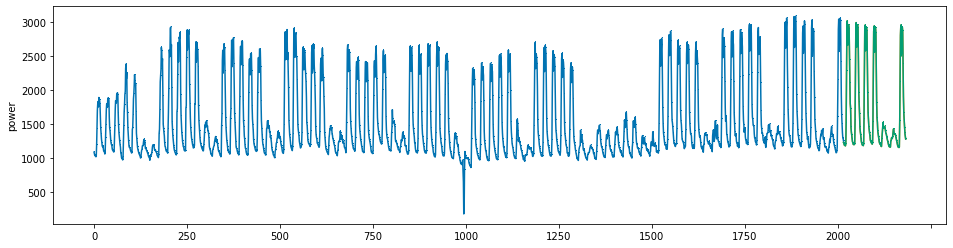
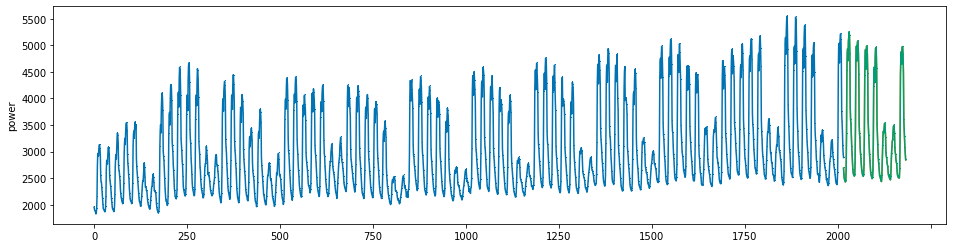
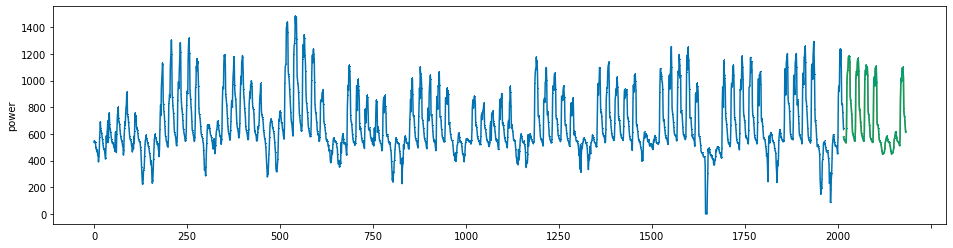
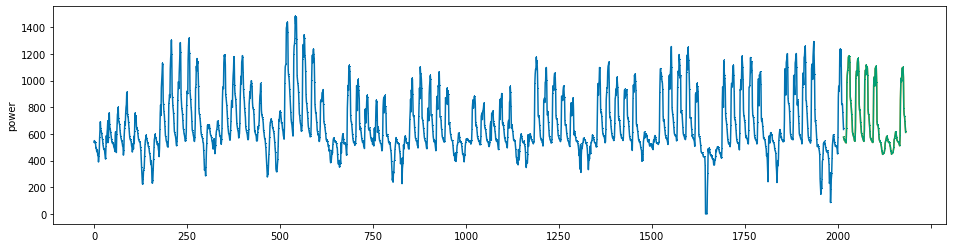
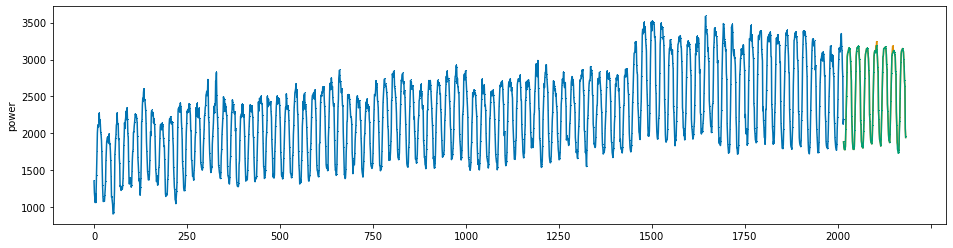
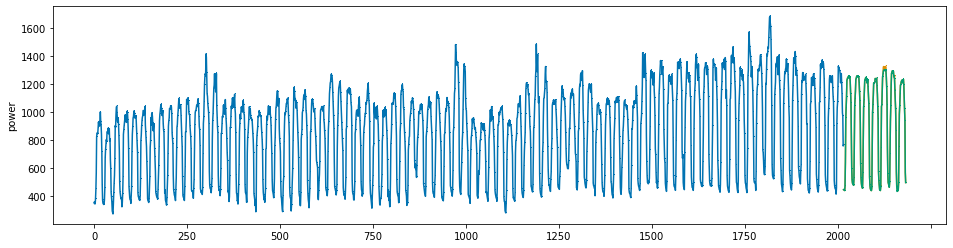
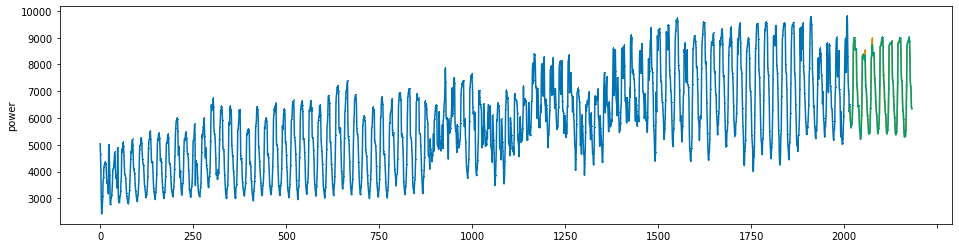
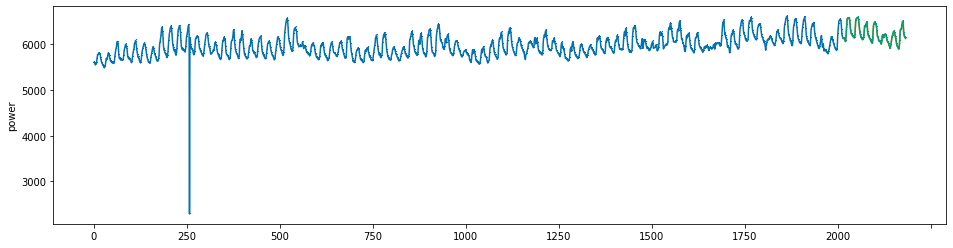
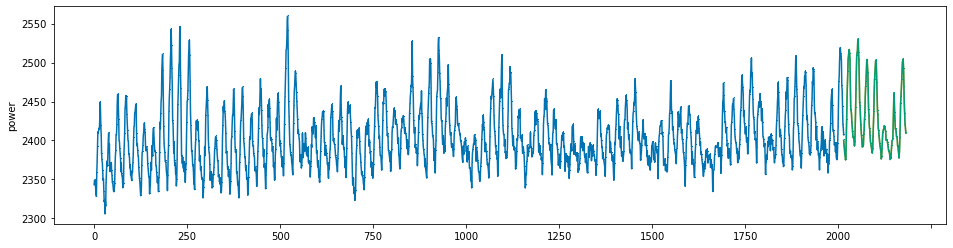
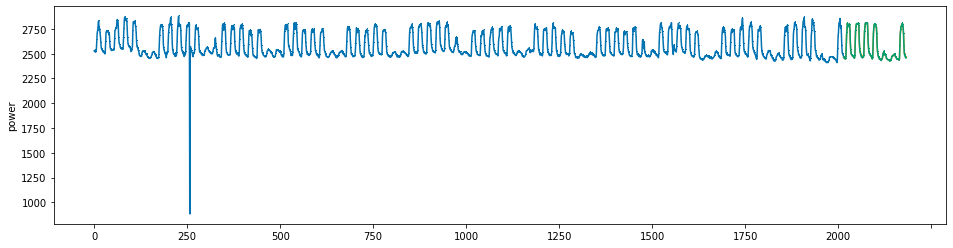
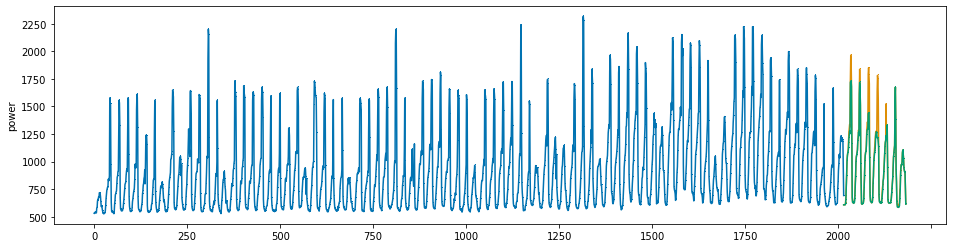
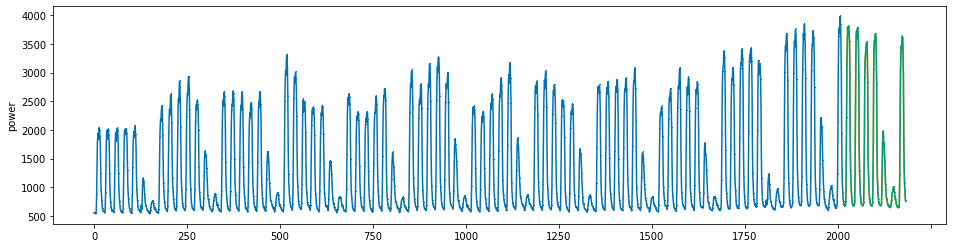
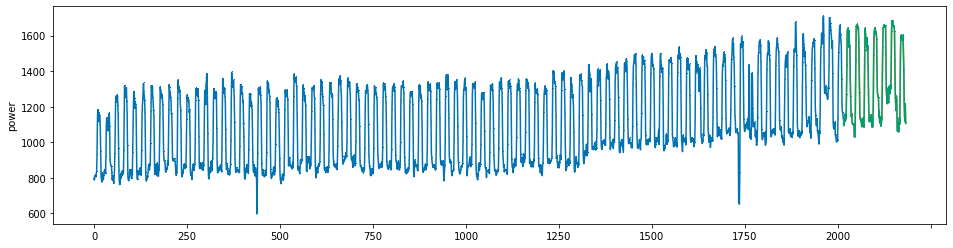
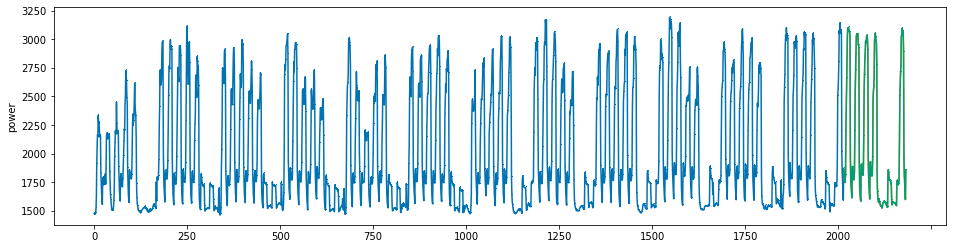
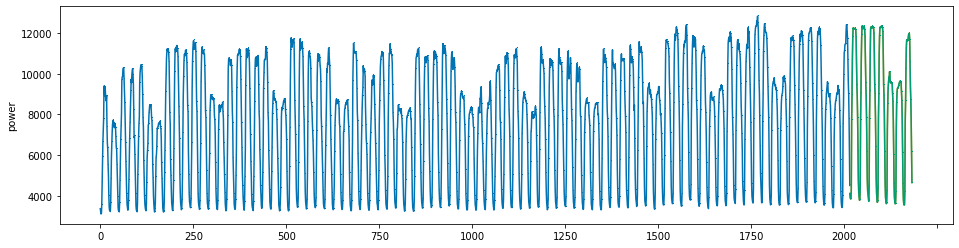
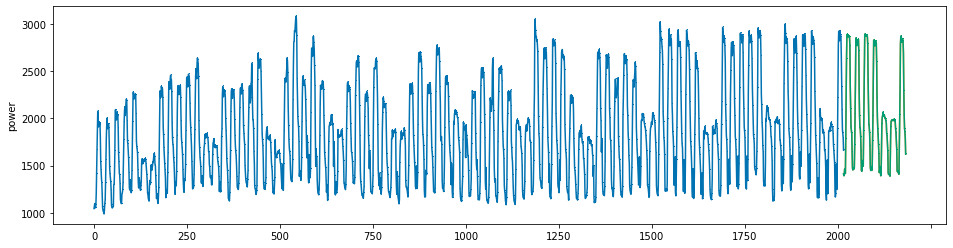
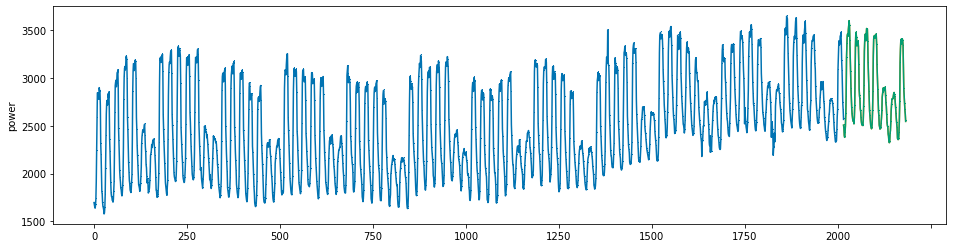
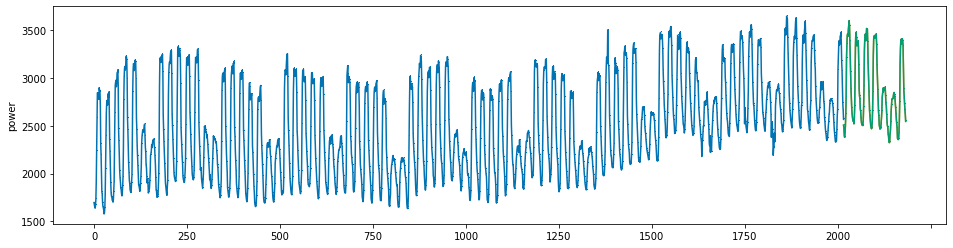
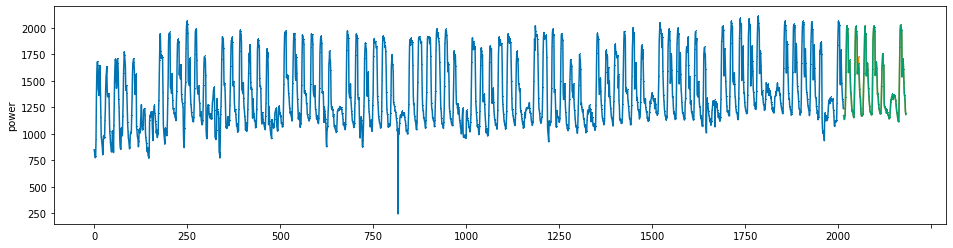
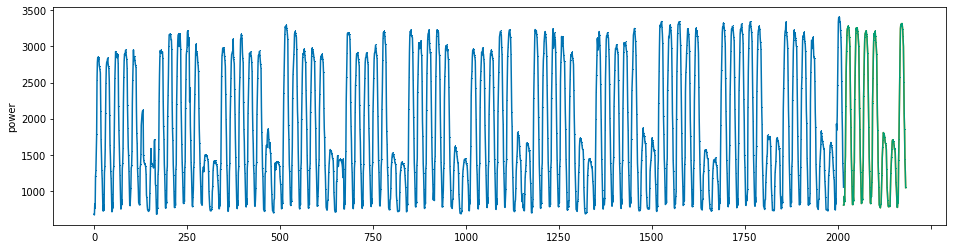
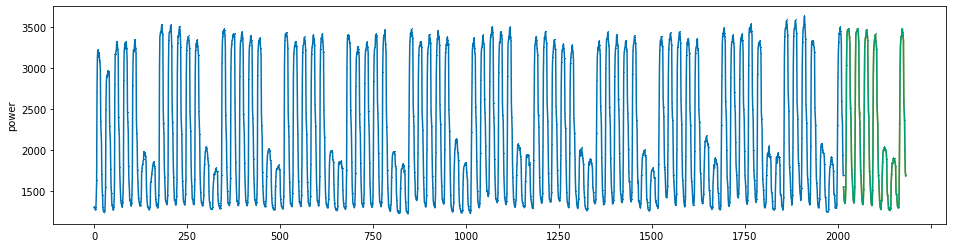
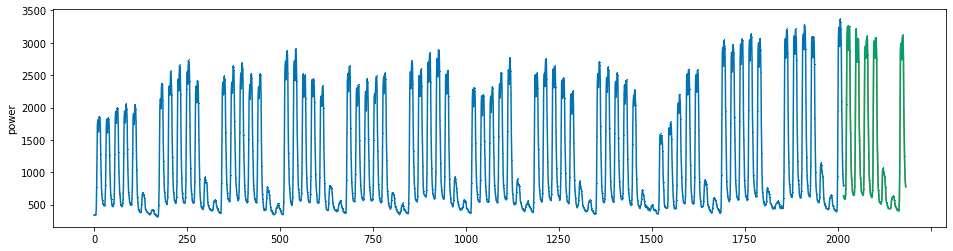

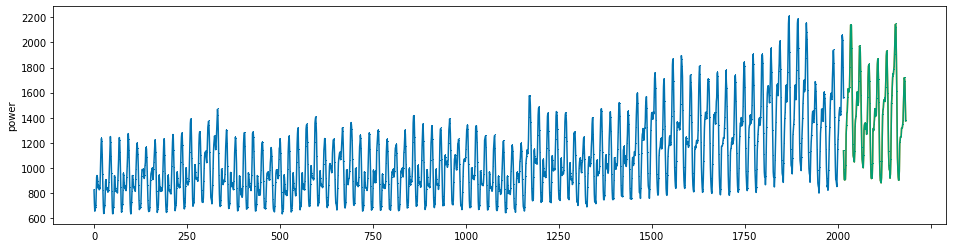
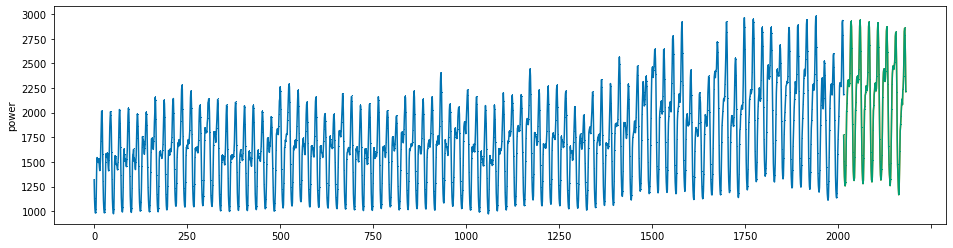
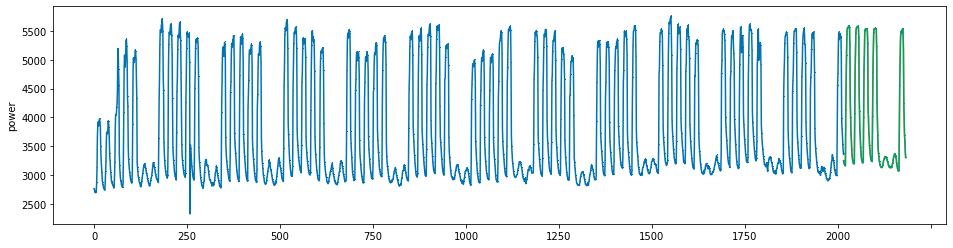
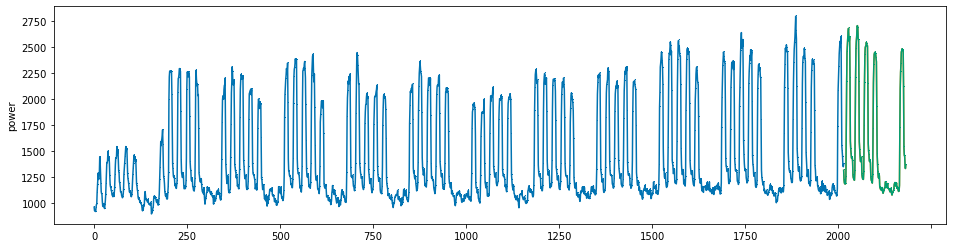
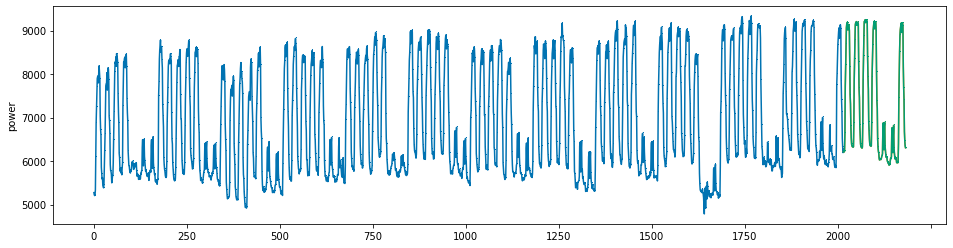

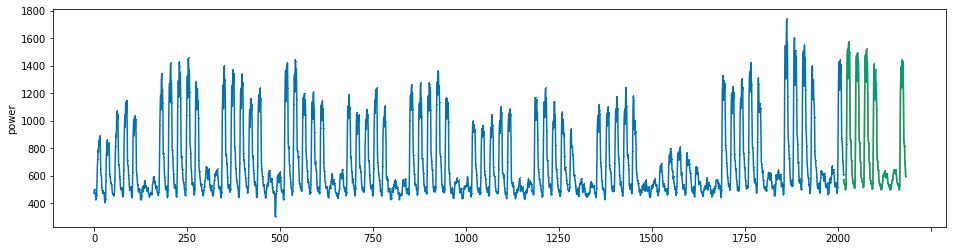
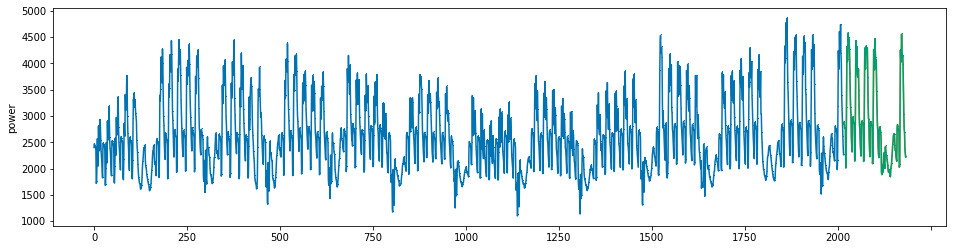
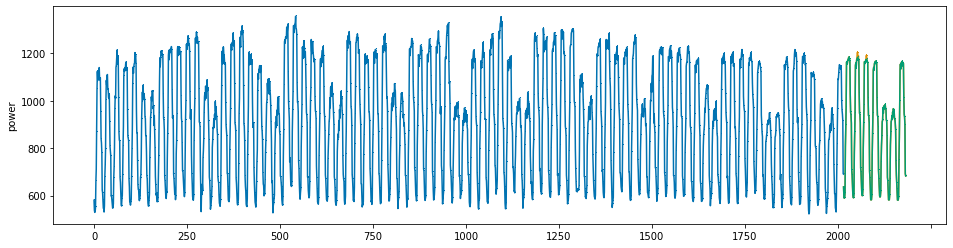
create submission file¶
submission = pd.read_csv('./data/sample_submission.csv')
submission['answer'] = pred_clip
submission.to_csv('./submission//submission_xgb_final.csv', index = False)