대상 : 2021년 다소비업체 전력사용량 건물부문 데이터 : 한전 실시간 데이터, 에너지사용량신고 데이터
In [1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
In [2]:
plt.rcParams['figure.figsize'] = (14, 9)
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['font.size'] = 12
plt.rcParams['axes.unicode_minus']
Out[2]:
In [3]:
df_b = pd.read_pickle('building_site.pkl')
df_b
Out[3]:
In [4]:
def basic_graph(data, sector):
grp_day = data.groupby('dt(날짜)')['전력사용량(kWh)'].sum() / 1000 # 시간 데이터->일 데이터 변환
#print(grp_day)
grp_day.plot()
plt.ylabel('전력소비량(kWh)')
plt.xlabel('일(day)')
plt.suptitle(f'{sector}부문 일일 전력소비량(MWh)')
plt.grid()
plt.show()
# 전체를 날짜, 시간으로 구분 후 요일 및 주 추가
grp_hour = data.groupby(['dt(날짜)', 'tm(시간)'])['전력사용량(kWh)'].sum() / 1000
grp_hour = grp_hour.reset_index()
grp_hour['weekday'] = grp_hour['dt(날짜)'].dt.weekday
grp_hour['weekofyear'] = grp_hour['dt(날짜)'].dt.weekofyear
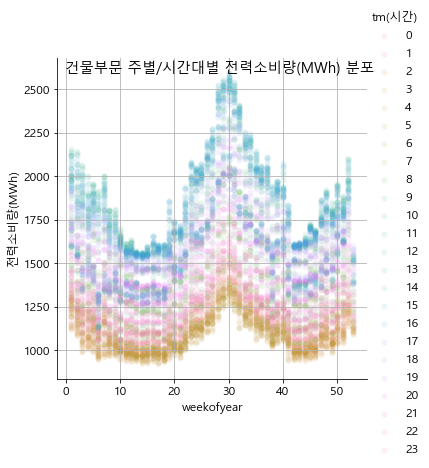
# 시간대별 전력소비량을 산포도 형태의 그래프로 그림
sns.pairplot(grp_hour, x_vars=['tm(시간)'], y_vars='전력사용량(kWh)', hue='tm(시간)', height=5, plot_kws={'alpha':0.1, 'linewidth':0})
plt.ylabel('전력소비량(MWh)')
plt.xlabel('시간')
plt.suptitle(f'{sector}부문 시간대별 전력소비량(MWh) 분포')
plt.grid()
plt.xticks(np.arange(24), labels=list(range(1, 25)))
plt.show()
# 요일별 전력소비량을 산포도 형태의 그래프로 그림
sns.pairplot(grp_hour, x_vars=['weekday'], y_vars='전력사용량(kWh)', hue='tm(시간)', height=5, plot_kws={'alpha':0.1, 'linewidth':0})
plt.ylabel('전력소비량(MWh)')
plt.suptitle(f'{sector}부문 요일별/시간대별 전력소비량(MWh) 분포(월-금, 토, 일')
plt.grid()
plt.xticks(np.arange(7), labels=['월', '화', '수', '목', '금', '토', '일'])
plt.show()
# 주/시간별 전력소비량을 산포도 형태의 그래프로 그림
sns.pairplot(grp_hour, x_vars=['weekofyear'], y_vars='전력사용량(kWh)', hue='tm(시간)', height=5, plot_kws={'alpha':0.1, 'linewidth':0})
plt.ylabel('전력소비량(MWh)')
plt.suptitle(f'{sector}부문 주별/시간대별 전력소비량(MWh) 분포')
plt.grid()
plt.show()
In [6]:
basic_graph(df_b, '건물')
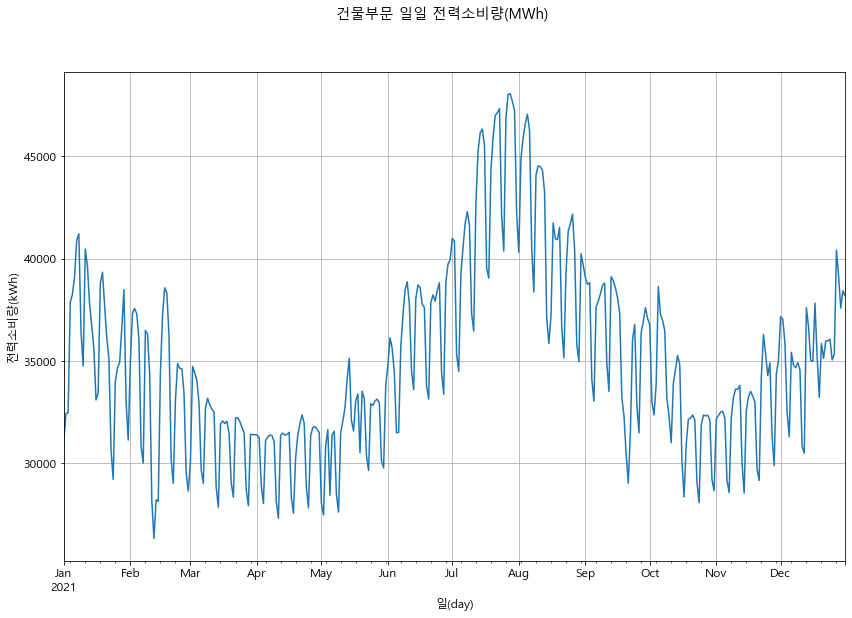
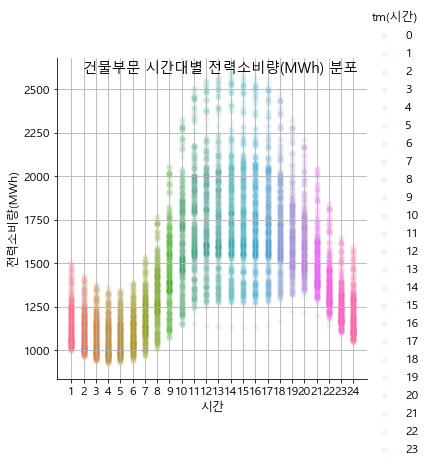
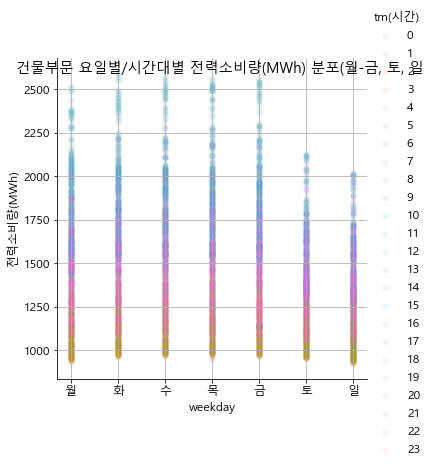
In [7]:
df_p = pd.read_pickle('building_pivot.pkl')
df_p
Out[7]:
In [10]:
def load_profile(df_pivot, sector):
# 시간별 전력소비량만 정규화
df_pivot.iloc[:, 3:27] = df_pivot.iloc[:, 3:27].apply(lambda x : x/x.max(), axis=1)
df_pivot['weekday'] = df_pivot['dt(날짜)'].dt.dayofweek # 요일 컬럼 추가
#print(df_pivot.head())
df_wk = df_pivot[df_pivot['weekday'] <= 4] # 주중
df_wn = df_pivot[df_pivot['weekday'] > 4] # 주말
# 전체, 주중, 주말 데이터 도출
grp_all = df_pivot.groupby('kemc_oldx_code_tite')[list(range(0, 24))].mean() * 100
grp_wk = df_wk.groupby('kemc_oldx_code_tite')[list(range(0, 24))].mean() * 100
grp_wn = df_wn.groupby('kemc_oldx_code_tite')[list(range(0, 24))].mean() * 100
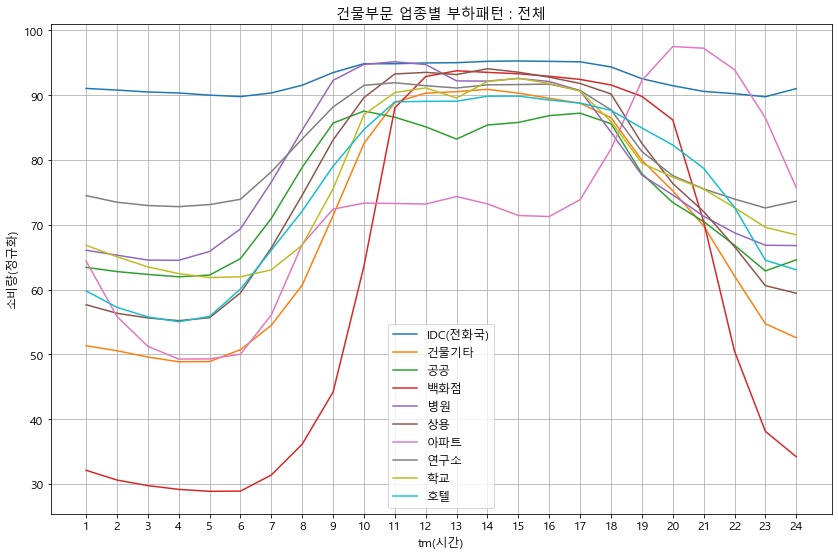
grp_all.T.plot()
plt.ylabel('소비량(정규화)')
plt.title(f'{sector}부문 업종별 부하패턴 : 전체')
plt.legend(loc='best')
plt.grid(which='both')
plt.xticks(np.arange(24), labels=list(range(1, 25)))
plt.show()
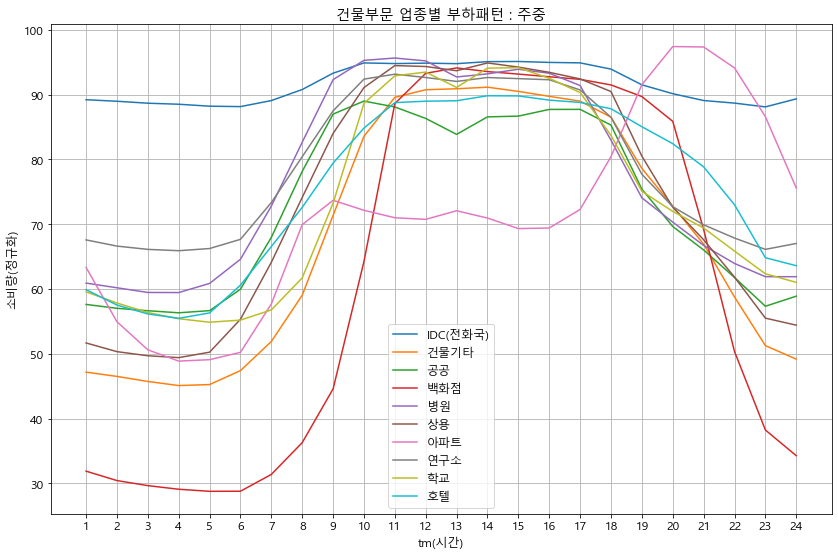
grp_wk.T.plot()
plt.ylabel('소비량(정규화)')
plt.title(f'{sector}부문 업종별 부하패턴 : 주중')
plt.legend(loc='best')
plt.grid(which='both')
plt.xticks(np.arange(24), labels=list(range(1, 25)))
plt.show()
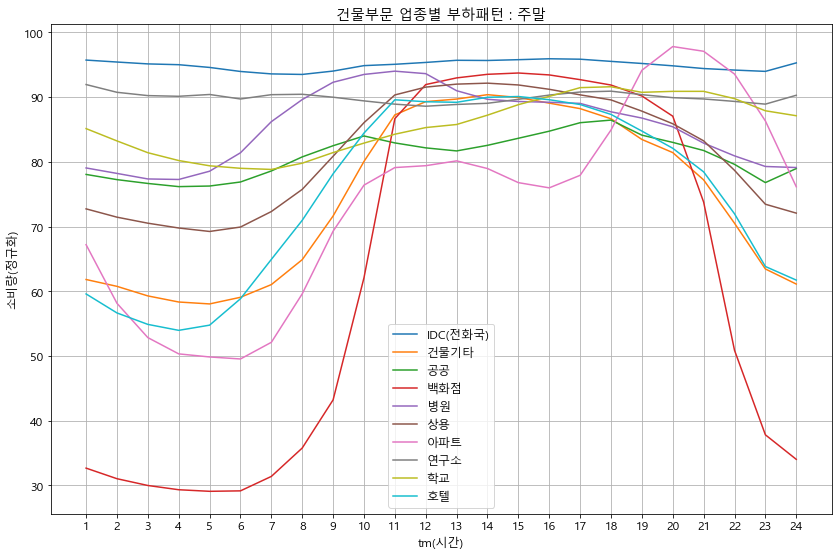
grp_wn.T.plot()
plt.ylabel('소비량(정규화)')
plt.title(f'{sector}부문 업종별 부하패턴 : 주말')
plt.legend(loc='best')
plt.grid(which='both')
plt.xticks(np.arange(24), labels=list(range(1, 25)))
plt.show()
In [11]:
load_profile(df_p, '건물')
In [12]:
def load_factor(data, sector):
# 일자별 부하율 계산
data['LF'] = data.drop(['ente'], axis=1).mean(axis=1) / data.drop(['ente'], axis=1).max(axis=1) * 100
# 용도별/월별 부하율 계산
data['month'] = data['dt(날짜)'].dt.month
pivot_lf = pd.pivot_table(data, index='kemc_oldx_code_tite', columns='month', values='LF', aggfunc=np.mean)
#print(pivot_lf)
pivot_lf.T.plot()
plt.ylabel('부하율(%)')
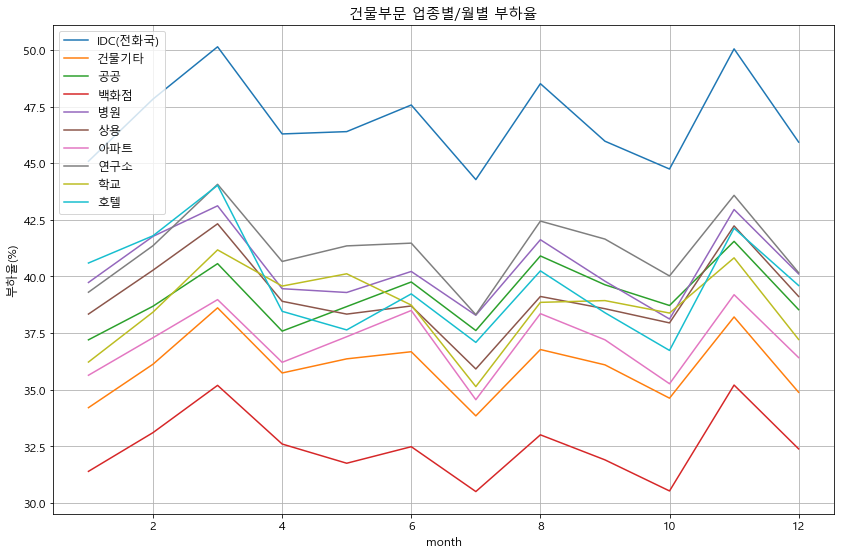
plt.title(f'{sector}부문 업종별/월별 부하율')
plt.legend(loc='best')
plt.grid(which='both')
plt.show()
sns.boxplot(x='month', y='LF', data=data)
plt.ylabel('부하율(%)')
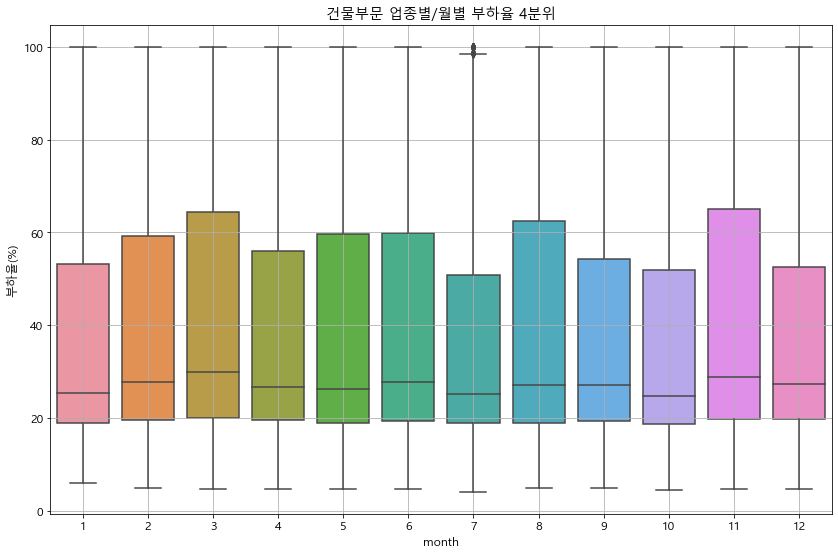
plt.title(f'{sector}부문 업종별/월별 부하율 4분위')
plt.grid(which='both')
plt.show()
In [13]:
load_factor(df_p, '건물')
In [14]:
def detail_type(data):
#print(data.head())
for idx in data['kemc_oldx_code_tite'].unique():
btype = data[data['kemc_oldx_code_tite'] == idx].copy() # 용도별 구분
btype.iloc[:, 3:27] = btype.iloc[:, 3:27].apply(lambda x : x/x.max(), axis=1) # 정규화
btype_site = btype.groupby('ente')[list(range(0, 24))].mean() # 용도의 시간별 평균 계산
btype_site_mean = btype_site.mean()
btype_site.T.plot(alpha=0.7, linewidth=0.7)
btype_site_mean.plot(linewidth=3)
plt.grid()
plt.legend().remove()
plt.xlabel('시간')
plt.ylabel('전력소비량(정규화)')
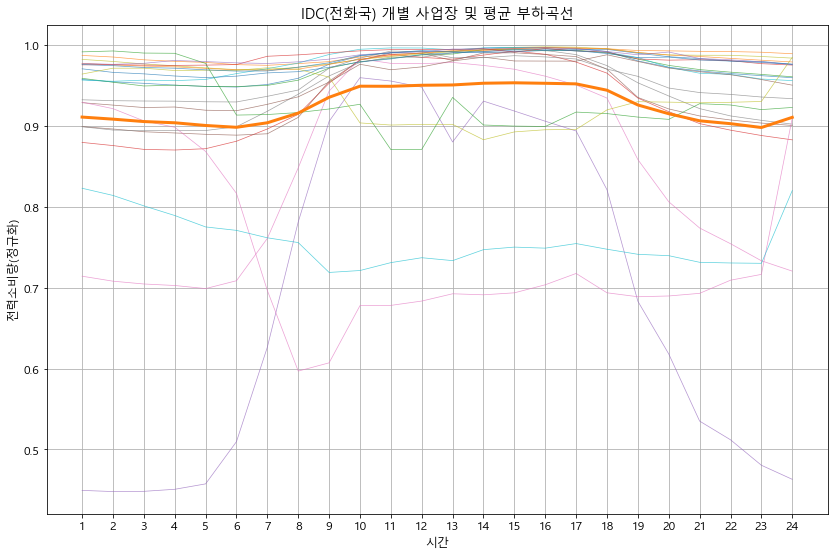
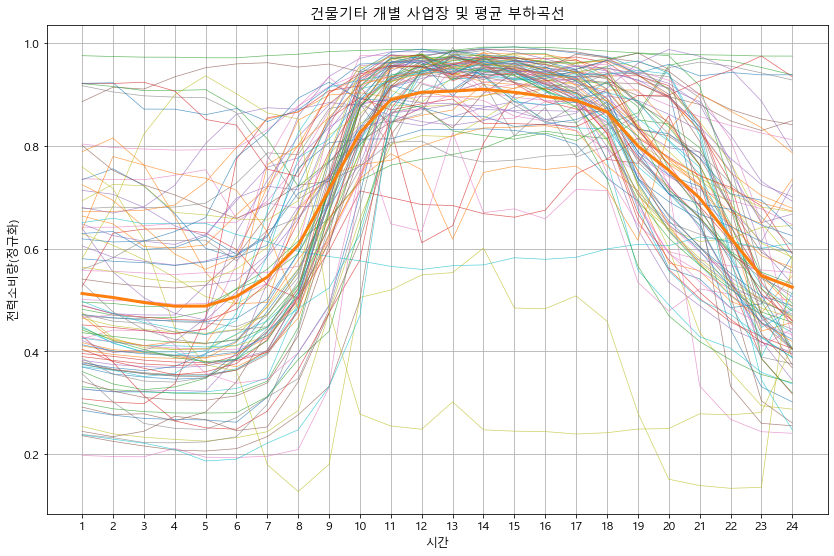
plt.title(f'{idx} 개별 사업장 및 평균 부하곡선')
plt.xticks(np.arange(24), labels=list(range(1, 25)))
plt.show()
In [15]:
detail_type(df_p)
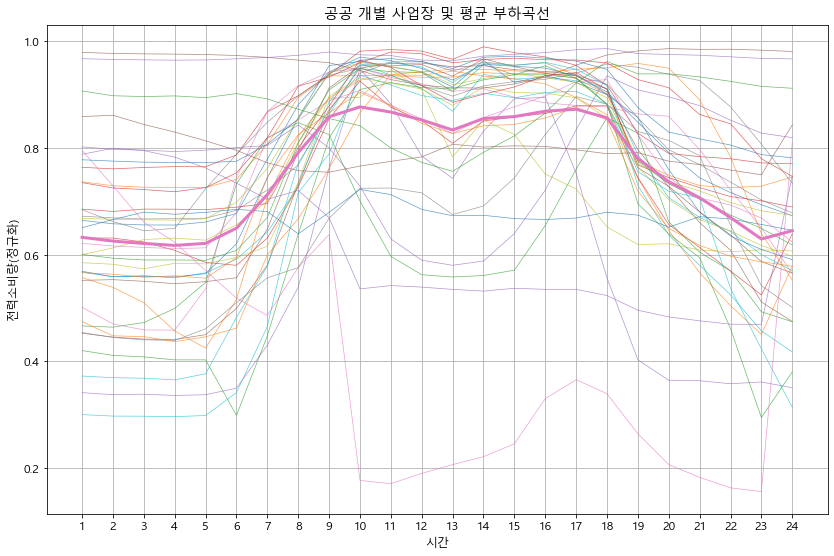
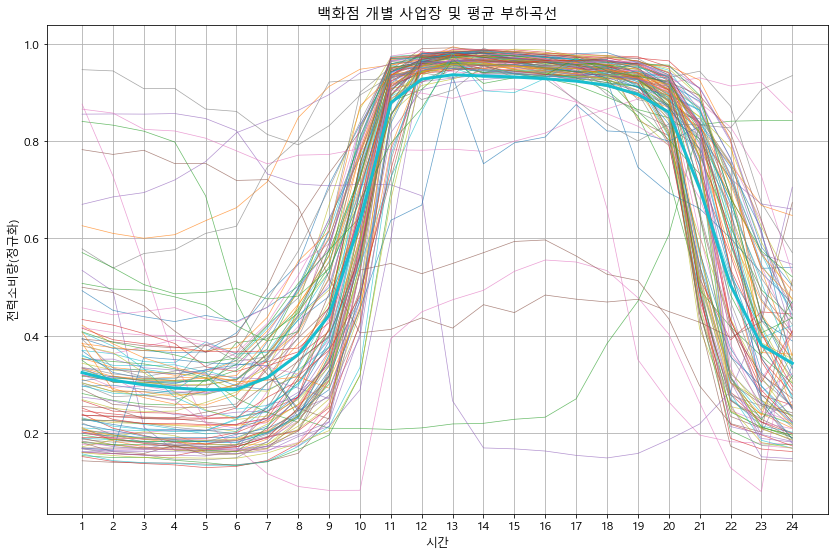
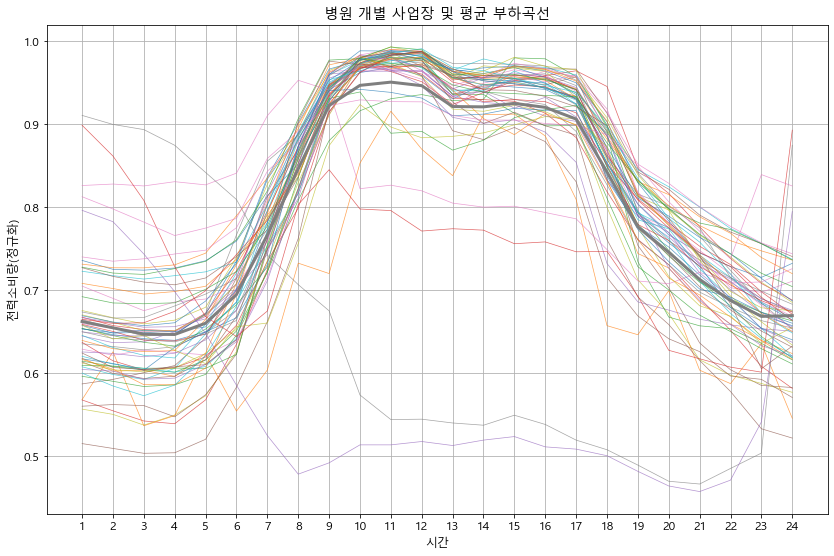
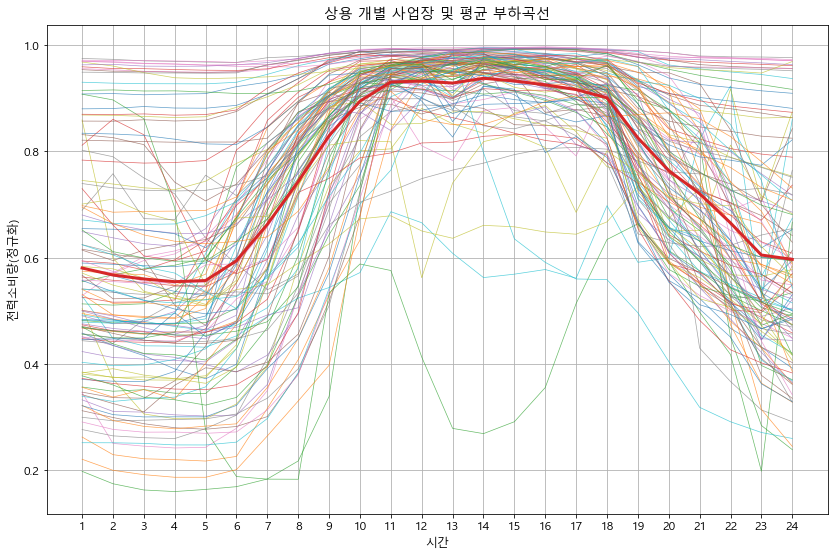
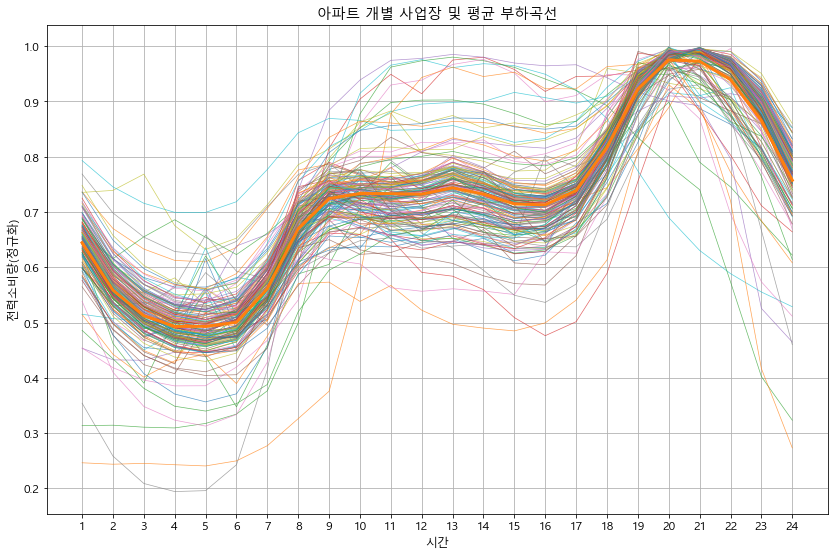
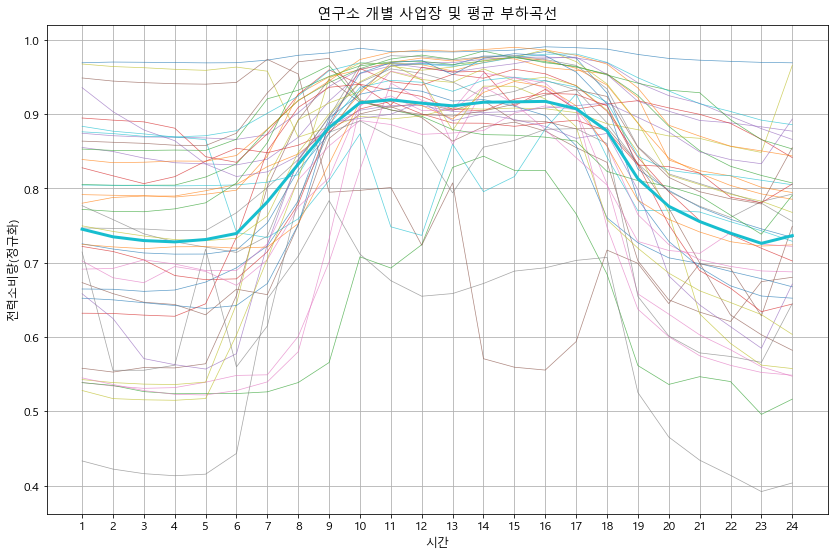
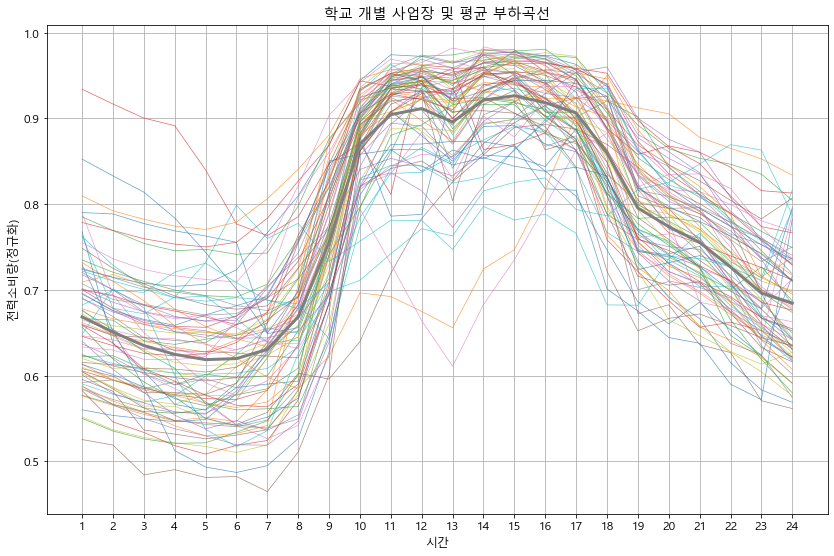
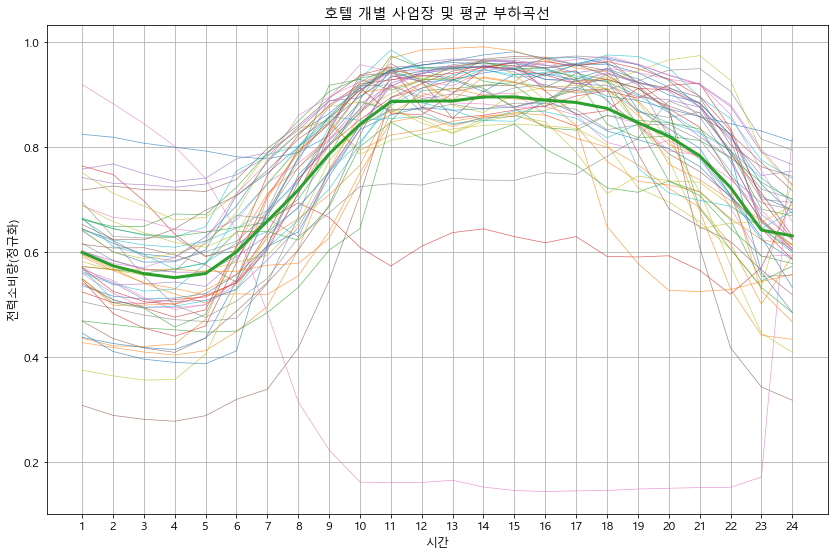
In [18]:
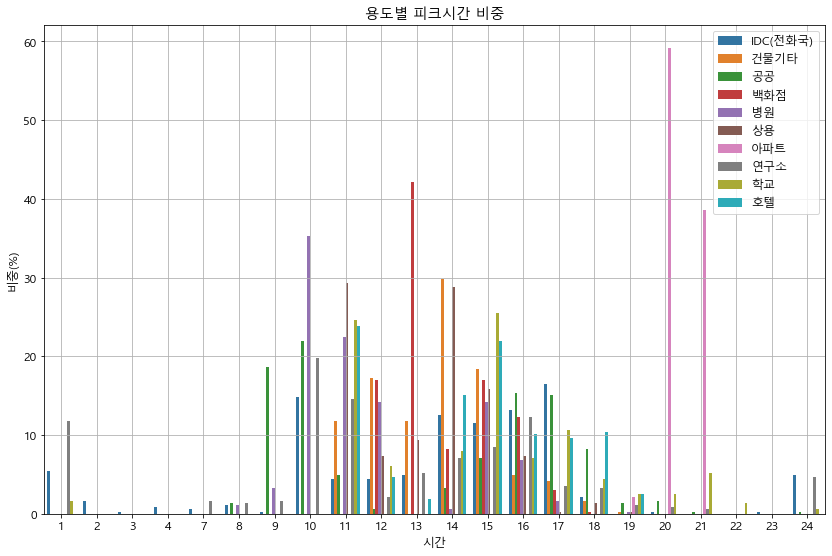
def peak_hour(data):
#print(data.head())
grp_type = data.groupby(['kemc_oldx_code_tite', 'dt(날짜)'])[list(range(0, 24))].sum()
grp_type = grp_type.reset_index()
grp_type['peak'] = grp_type[list(range(0, 24))].idxmax(axis=1) # 하루 중 피크인 시간대 도출
bar_type = grp_type.groupby('kemc_oldx_code_tite')['peak'].value_counts() # 시간대별 피크인 사업장수 도출
bar_type = bar_type.unstack().fillna(0)
bar_type.iloc[:, :] = bar_type.iloc[:, :].apply(lambda x: x / x.sum(), axis=1) * 100
bar_type_stack = bar_type.stack()
bar_type_stack = bar_type_stack.reset_index()
bar_type_stack.columns = ['type', 'hour', 'peak']
bar_type_stack['hour'] = bar_type_stack['hour'] + 1
sns.barplot(data=bar_type_stack, x='hour', y='peak', hue='type')
plt.grid()
plt.legend()
plt.xlabel('시간')
plt.ylabel('비중(%)')
plt.title('용도별 피크시간 비중')
plt.show()
In [19]:
peak_hour(df_p)